Work Packages
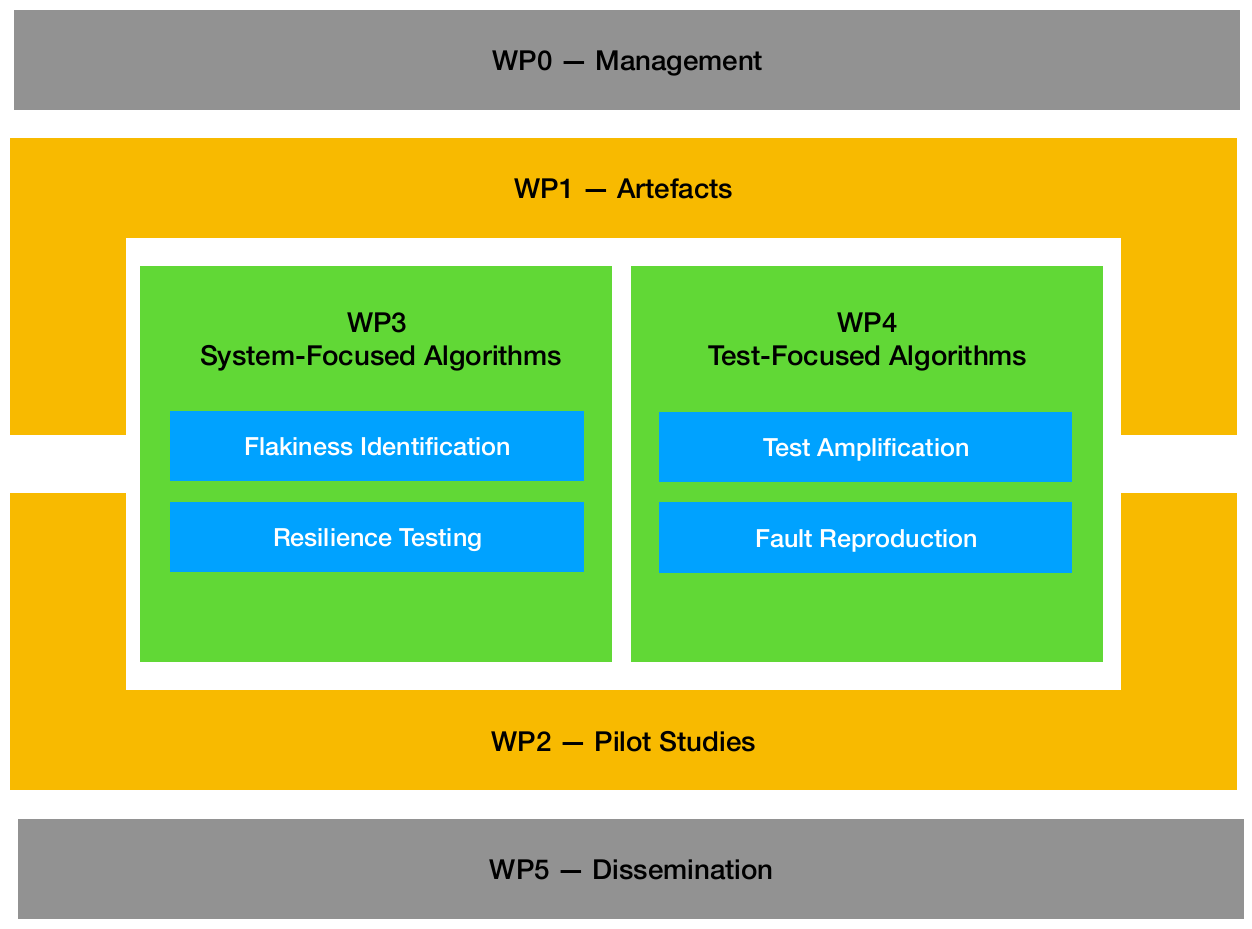
WP1: Artefacts
The goals of WP3 and WP4 are to develop novel algorithms for zero-touch testing, which we will implement into practical tools.
To amortise the engineering effort of developing these tools, they will be built on top of jointly-maintained infrastructure such as meta-models and frameworks for representing cloud-native applications, extracting knowledge from Infrastructure-as-Code files, representing tests and test outcomes, integrating with an IDE or a DevOps pipeline, etc.
The datasets required for the evaluation of these applications will also be jointly composed and curated. Consistent with our dissemination strategy, we will make these dataset publicly available in order to allow for replication of research results and ultimately accelerate international research activities.
WP2: Pilot Studies
Once the algorithms from WP3 and WP4 have been prototyped and implemented, we will run pilot studies of these tools with members of our Advisory Committee. This in order to validate them in their intended industrial context and to stress-test these tools to reveal shortcomings or potential further research opportunities.
WP3: Sytems-Focused Algorithms
WP3 investigates those techniques which primarily focus on the system under test.
Flakiness Identification
First, we will attempt to identify the root causes and symptoms of flaky tests in cloud-native applications.
The next step is to collect algorithms for identifying flaky tests by monitoring which tests flip results on subsequent test runs to establish a flakiness score. This will start from the state of the eart and attempt to tap into version control systems to identify whether the flipped test is caused by a commit or whether the test is actually flaky.
Finally, we will use our expertise with fault localisation to create a tool for mitigating the most harmful flaky tests.
Resilience Testing
We aim to automatically identify mistakes in the implementation of resilience tactics against failures commonly encounterd in the cloud.
For this purpose, we will first analyse the potential for defects in cloud-native resilience tactics, looking at the emerging design pattern literature for microservices and serverless. Using the resulting catalogue of resilience defects, we will formalise the faults that need to be injected to expose it in a failure scenario.
We will then develop a tool that accepts these failure scenarios and applies them to systems to test their resilience. While initially this tool will work manually, we will expand it with the ability to augment failure scenarios with insights extracted from the source code and accompanying Infrastructure-as-Code files.
Finally, we will make the tool autonomous by efficiently exploring the space of all possible failures that may be injected to expose a fault. This will require novel pruning algorithms and prioritisation heuristics, based on run-time feedback from the system under test.
WP4: Test-Focused Algorithms
WP4 investigates techniques which try to improve and extend the test suite itself.
Test Amplification
The goal of the test amplification task is to adapt "happy-day" test scenarios to exercise boundary conditions. We will do this by developing a tool for input amplification of system level regression tests. It will assess which of the generated test inputs exercise boundary conditions, using mutation testing.
We will then expand this tool with assert amplification, allowing it to insert additional assert statements that reveal the fault.
Finally, we will enhance this tool by making the generated tests more understandable. The tool should generate meaningful names for the test itself, as well as for the extra state variables it introduces.
Fault Reproduction
With fault reproduction, we aim to automate the generation of new test cases that faithfully recreate reported failures. To this end, we will develope a mechanism that integrates stack trace analysis into the test generation process.
First, we will map clues extracted from stack traces to relevant program elements, steering test case generation toward reproducing the failure. This involves associating stack trace information with specific API interactions and program execution paths, allowing the tool to focus on scenarios that are most likely to reproduce the reported issue.
To enhance efficiency, we will incorporate mechanism that prioritizes the exploration of event sequences. These heuristics leverage the architecture of cloud-native applications to optimize test case generation, reducing unnecessary requests while maintaining accuracy in reproducing failures.
Finally, we will accelerate failure reproduction by integrating symbolic execution summaries. These summaries streamline the reproduction process by capturing and reusing key execution patterns, minimizing redundant test cases and reducing the overall computational overhead.